
꿈을 향해 on my way
초간단 웹 스크레이핑 / 웹 크롤링 (크롬 익스텐션 - Web Scraper) 본문
1. 크롬 익스텐션 - 'Web Scraper' 설치 (webscraper.io/)


webscraper.io 에서 위의 스크린샷과 같이 프로그램을 다운받으면 설치가 끝납니다. (보통 크롬 익스텐션 프로그램은 다운로드 후 오른쪽 상단에 아이콘이 생기는데 이건 안생깁니다. 괜찮아요. 당황하지 않으셔도 됩니다. 'Developer tool' 을 키면 보임)
2. Web Scraper Tool bar 열기
Web Scraper Tool bar 를 열려면 Developer Tool 창을 열어야 합니다.
- 단축키 'Ctrl + Shift + I' 로 켜도 되고
- 우측 세팅 아이콘을 이용해 'More tools' -> 'Developer Tool' 로 키셔도 됩니다.


위의 사진 내 아이콘을 이용해 Dock side를 하단으로 바꿔줍니다.

그럼, 이제 Developer Tool 메뉴바에 'Web Developer' 가 보입니다.
3. Sitemap 만들기
Sitemap은 웹마스터가 크롤링에 사용할 수 있는 사이트의 페이지에 대한 정보를 검색 엔진에 알리는 손쉬운 방법입니다. Sitemap의 가장 간단한 형식은 검색 엔진에서 사이트를 보다 지능적으로 크롤링할 수 있도록 각 URL에 대한 추가 메타데이터(마지막 업데이트된 날짜, 변경 빈도, 사이트의 다른 URL에 상대적인 중요도)와 함께 사이트에 대한 URL을 나열하는 XML 파일입니다.
무슨말인지 저도 100%는 모르겠습니다. 다만, 여기서 사이트맵이란, Web Scraper 프로그램이 웹 스크레이핑 (웹 크롤링)에 사용할 수 있도록 사이트의 페이지에 대한 정보를 제공하는 매체라고 이해하면 될 듯합니다.
Sitemap을 만들어보죠.


Sitemap name은 원하시는 아무 이름을 적으시면 되고, Start URL은 크롤링 할 웹페이지 주소를 적으면 됩니다.
(예시의 경우엔 rent.heykorean.com/rent/list)
4. Data Selector 만들기
이제, Sitemap 내에서 어떤 정보를 가져올지 선택해줍시다.
(아래의 예시에서 제가 원하는 정보는 각 부동산 매물의 제목과 조회수 입니다)
각 포스팅 안에 제목과 조회수 정보가 있죠. 먼저, 각 포스팅을 선택해줍니다.


각 포스팅이 하나의 element_wrapper 가 됩니다.
Id는 원하시는 이름 아무거나 적으면 되고, Type은 'Element', Multiple은 체크해줍니다.
(Element라는 Type이 생소하실 수도 있는데 HTML에서 Element (요소)는 HTML을 구성하는 세포라고 이해하시면 됩니다. 각 HTML Element는 시작태그와 종료태크, 그리고 그 사이의 내용(content)로 구성됩니다)

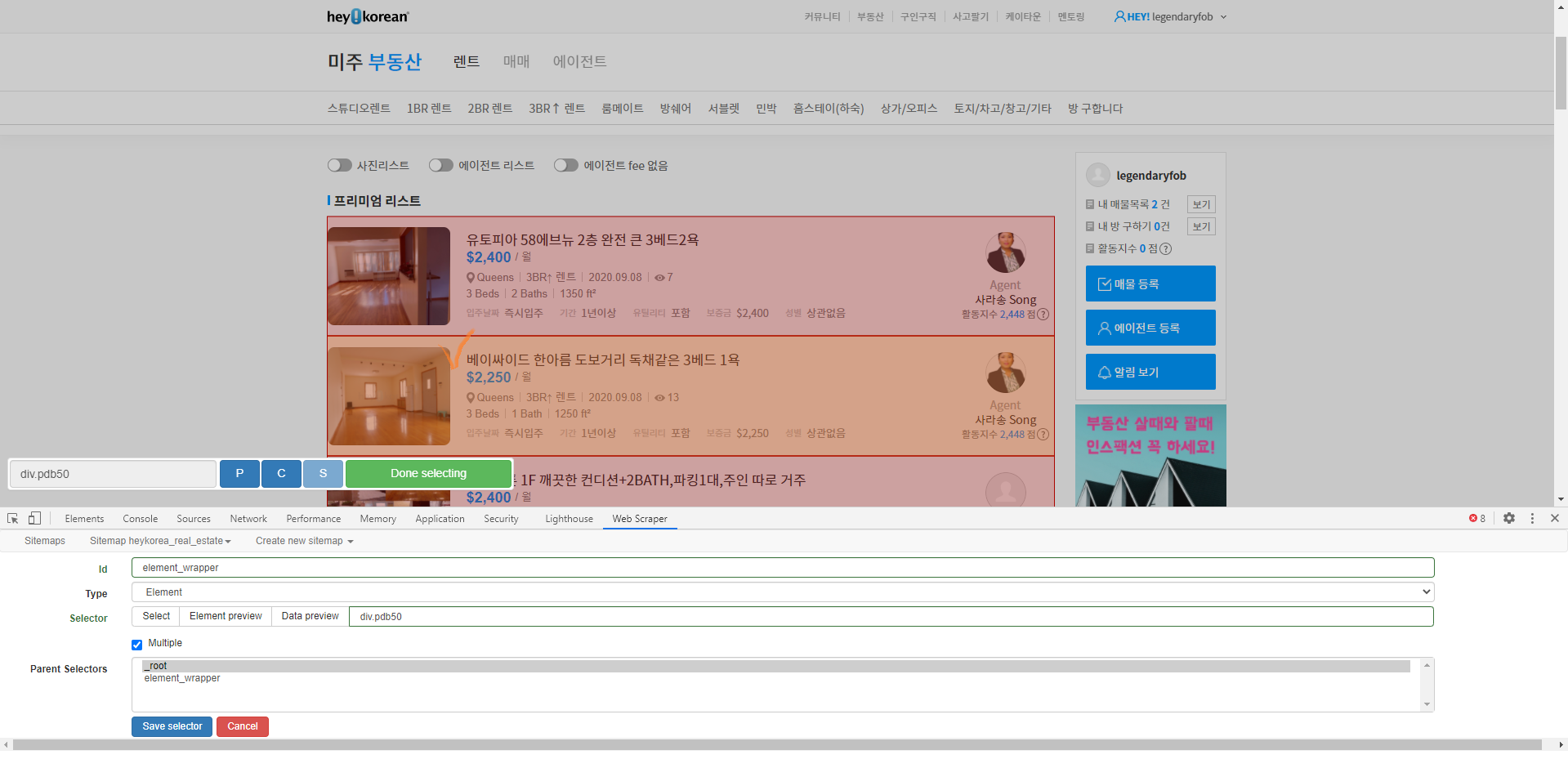
Select 버튼을 누르고 각 포스팅을 위의 사진처럼 클릭해줍니다. 제일 중요한건 초록색 'Done Selecting' 클릭까지!
이제 각 포스팅 (Element) 안에 어떤 정보를 스크레이핑 할건지 선택해 줍니다.
아까와 같은 방법으로 'Add New Selector'를 클릭하고 아래와 같이 입력

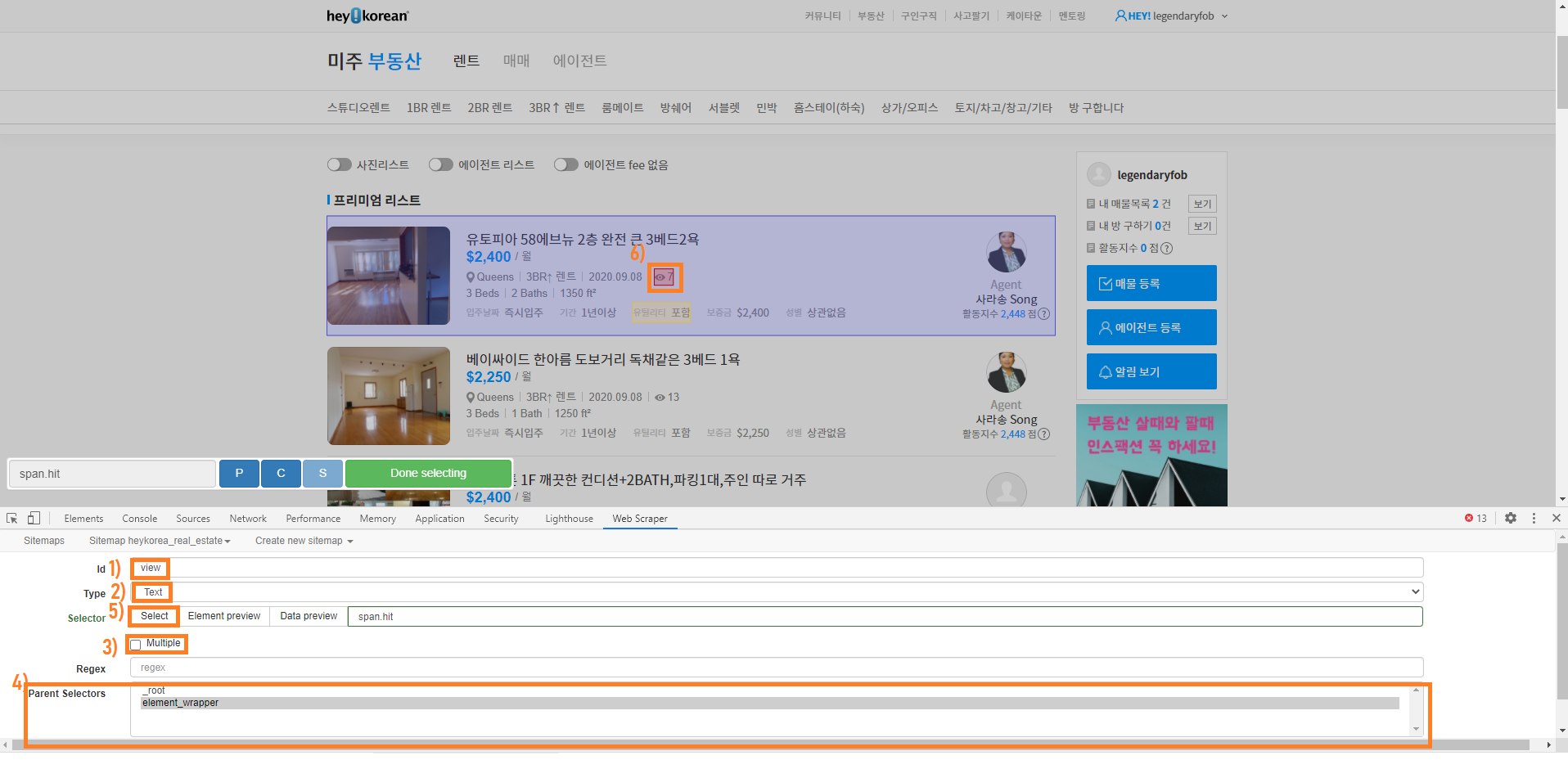
주의할건 Multiple 박스는 노체크, Parent Selector는 각 포스팅(Element) 안의 정보이니 'element_wrapper'를 클릭
5. Scraper 실행 & 데이터 다운로드
여기까지 했으면, 99%는 끝났습니다. 이제 설정한 사이트맵으로 크롤링만 하면 끝.




그럼, CSV 파일이 다운로드 됩니다. 다운 받아진 CSV을 열어보면 아래와 같습니다.
계획했던대로, title과 view 데이터가 깔끔하게 정리된 걸 볼 수 있습니다.

끝!
P.S. Python request 라이브러리와 beautifulsoup 라이브러리로 웹스크레이핑 하는 방법을 알고 있었는데, 좀 복잡했어요. 구글링 중에 정말 간단하게 웹스크레이핑/ 웹크롤링을 도와주는 크롬 익스텐션 프로그램을 발견해서 공유합니다. 직관적이고 정말 편하네요.
'데이터 사이언스 공부' 카테고리의 다른 글
| Pandas - json_normalize 문제 총 정리 (0) | 2022.04.02 |
|---|---|
| 복잡한 JSON 파일 쉽게 처리하기 - 파이썬 (How to flatten complex JSON file in Python) (0) | 2022.04.02 |
| Webhook vs API 차이 (0) | 2022.01.26 |
| Connect MySQL database with Python (0) | 2021.12.22 |
| Using .env Files for Environment Variables in Python Applications (0) | 2021.12.22 |

